[WIP] Stage-Supervised Latent Reasoning for Single-Shot JavaScript Deobfuscation
2026
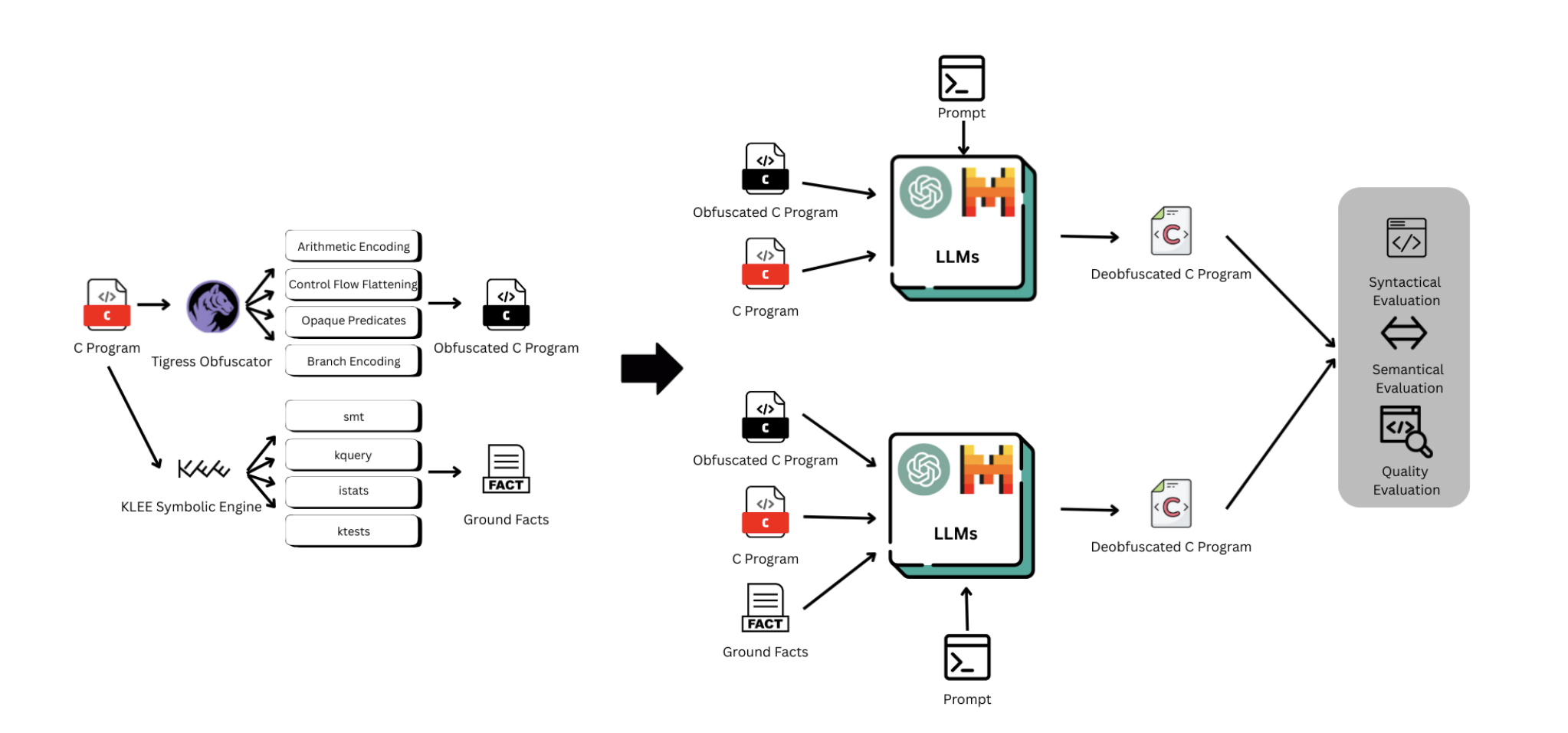
This WIP paper proposes a stage-aware latent reasoning framework for JavaScript deobfuscation. Rather than treating deobfuscation as a one-step translation, we convert intermediate outputs from the Webcrack deterministic deobfuscation pipeline into structured supervision for a Coconut-based model. The model learns from multi-stage rewrites during training but generates the final cleaned program in a single shot at inference time. Preliminary evaluation on JsDeObsBench shows the Coconut-based model achieves 50% syntactic validity and 80% semantic correctness among valid outputs, outperforming direct fine-tuning (15% syntax, 0% semantics) and a zero-shot baseline (25% syntax, 40% semantics).